Businesses are under constant pressure to reduce cost, driving IT organizations to consolidate standalone printers, copiers and fax machines across the enterprise. Gone are the days in which personal printers inhabited the offices of many employees. Now, office workers must share printers and multifunction devices with many co-workers in the area. While this approach results in a more optimal hardware infrastructure (e.g., higher-speed/capacity devices with lower print costs), it introduces a security issue in return. What prevents users from picking up the documents that were submitted earlier by other users? Nothing, unless a solution is implemented that prevents this from happening.
A popular solution to this general problem is called “pull printing.” Many vendors refer to it by different names, such as “secure printing, “secure release”.” This is where users submit documents for printing from their desktop, but the documents are held until users authenticate at a device and release them. More commonly, implementations involve the use of employee badges (proximity cards) that can be used in the authentication process.
The following diagram depicts a generic example of a pull printing solution:
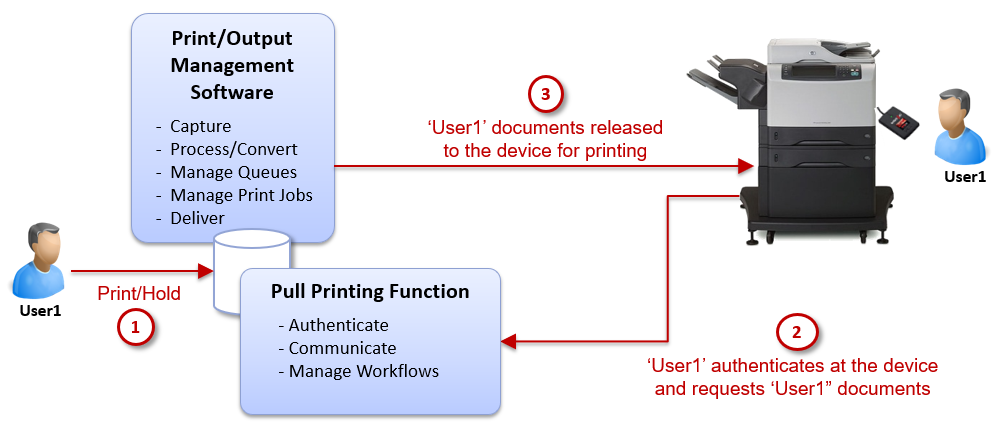
What about high-availability pull printing for large enterprise environments? Due to the authentication process and the holding of print jobs, the print workflow is a little more complicated than standard printing. For example, there is a longer time delay between print submission and the actual printing process at the device. Many print jobs can be held on a print server before being released to the print device. But what happens if the print server fails? Are the queued print jobs lost? Let’s explore this subject more.
LRS solutions are known for offering tremendous vertical scalability. Each LRS output management server can support many thousands of network print devices with no degradation of performance. This means that in most customer environments, only one active server is required. However, a server can fail for a variety of reasons, so no sensible IT organization would trust its production operation to a single server. Some level of redundancy is required to ensure that the business keeps running 7x24.
In the past, active-passive server clustering (e.g., Windows server cluster) was a common and acceptable approach to high availability; however, there is a growing preference to run multiple active servers behind a load balancer. The load balancer distributes the incoming workload across the servers, and it can dynamically switch traffic away from troubled or failed servers. This kind of HA configuration provides what is often referred to as horizontal scalability. Consider the following diagram:
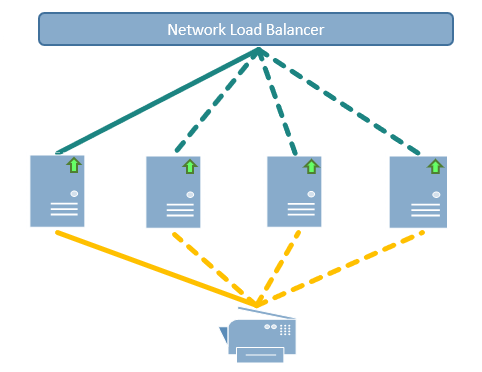
The servers may be configured to be active-passive or active-active. In active-passive mode, only one server is actively doing work until a failure occurs. The load balancer then directs the incoming workload to another server in the group. In an active-active configuration, each server in the group is actively processing work, and the load balancer attempts to distribute the incoming print jobs to avoid processing bottlenecks. When a server fails, the load balancer removes it from the server group and continues.
So, how does this kind of HA configuration support pull printing with potential server failures? Many competitive print management solutions rely on the use of a shared database across the servers. This database keeps a lot of information, including metadata about the users and print jobs. Unfortunately, the database does not keep a copy of the actual print jobs. This means that when a print server fails, the print jobs that were held on it (i.e., waiting for authentication and release by users) are no longer available to users.
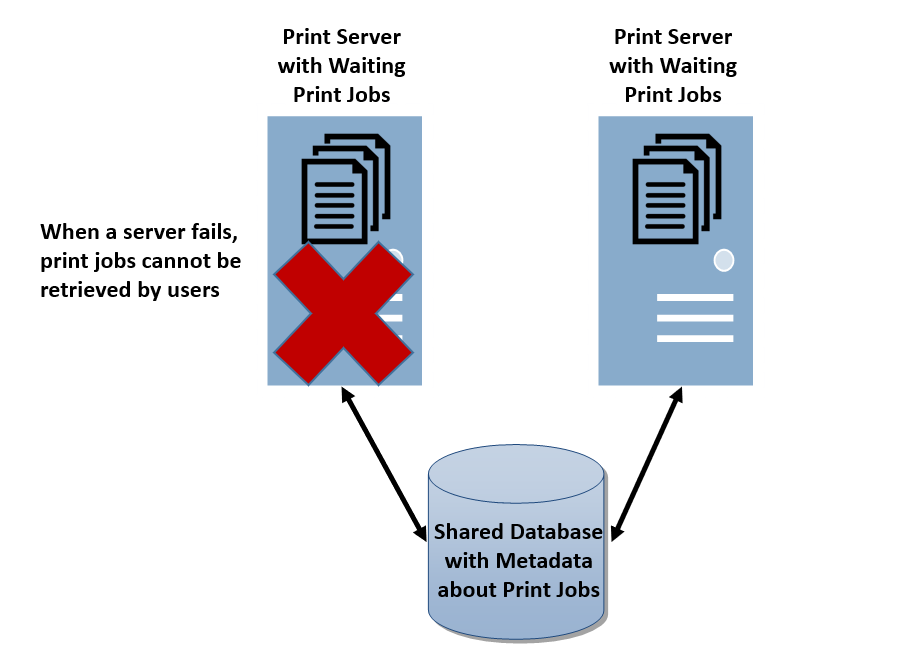
However, users are not aware of this problem. In fact, users will be able to authenticate at the print device and see their available print jobs for selection, but nothing will print. Can we really call that high availability? I can hear the helpdesk phones ringing now.
The LRS solution dynamically replicates each active server’s “state” across the other servers in the HA group, including print data and metadata. For example, if an IT administrator defines a new print queue on one server, this new queue definition is automatically replicated on the other servers in the group. See the illustration below:
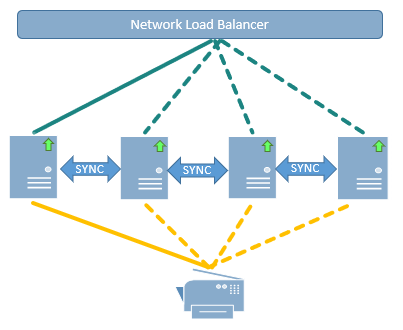
This HA architecture ensures that users will always be able to retrieve their documents at any supported device in the network. It also greatly simplifies the administrative tasks to maintain and upgrade the pull printing solution across a diverse enterprise. The organization can add servers as required to meet their operational requirements. LRS delivers true horizontal scalability with automated failover, so printing can continue without disruption after the failure of n-1 servers.
In summary, if any part of your HA solution doesn’t work, the whole thing doesn’t work. There are no prizes for providing “mostly high availability.” LRS provides the magic to make it all work, simply and reliably. Give us a call. We provide HA output management solutions to large enterprises worldwide, and I am confident that we can address your organization’s unique HA requirements.